
Key Takeaways:
What is Generative AI?
Using generative AI facilitates the creation of new content (text, images, videos, etc.) through generative models pre-trained on massive data sets. Its applications in fashion are vast.
Here’s an explicit overview of the different applications of generative AI along the value chain.

Now, it's time to explore each use case together to see how Gen AI can revolutionize the industry.
I/ AI in Fashion Design & Creation
The year 2026 marks a pivotal shift in fashion design, as the industry moves from general AI experimentation to the adoption of highly specialized tools that solve concrete problems within the creative workflow. These new platforms are re-engineering the entire process, from initial sketch to final material selection.
1) Breakthroughs in Material Simulation
Beyond visual design, AI is bringing scientific precision to fabric simulation. Style3D Fabric represents one of the most advanced breakthroughs in the field, offering high‑fidelity digital material models through a combination of fabric digitization, realistic physical simulation, 3D previewing, and AI‑assisted textile creation. Their 2026 platform emphasizes accurate prediction of fabric behavior—such as drape, stretch, weight, and deformation—allowing teams to evaluate materials long before physical prototypes are produced.
This enables fashion brands to anticipate how a textile will perform in real‑world conditions. For example, AI can simulate how an eco‑friendly fabric behaves in activewear, predict durability after repeated washing cycles, or model how smart‑textile fibers interact with the skin. These capabilities significantly reduce the need for costly and time‑consuming physical sampling rounds while improving material decision‑making early in the design process.

Seddi Textura 3D visual rendering | source: SEDDI Textura
2) Data-Augmented Creativity
AI is also becoming a key strategic partner in trend forecasting. Platforms like Adobe Sensei, Designify, and Fashwell now analyze massive datasets from past runway shows, social media aesthetics, and real-time customer preferences to help designers create more commercially viable collections. These tools can predict which silhouettes, colors, or fabrics are likely to resonate in upcoming seasons. Designers can input prompts and receive AI-generated mood boards, sample sketches, and even recommendations for sustainable fabrics, augmenting their creative intuition with data-driven insights.
3) Automated fashion design
Generative AI is revolutionizing fashion design by accelerating the creation of new collections. These tools allow creative teams to translate sketches into detailed, photorealistic renders in seconds, exploring fabrics, colors, and silhouettes at a pace impossible with traditional methods. A compelling recent example: in February 2026, ASOS embedded generative AI toolbox across its design operations, upskilling more than 100 designers in the process. The technology enables teams to instantly explore colorways, fabrics, and variations, improving communication with suppliers and increasing first-sample accuracy while reducing waste — with an average time saving of 75 to 80% across key design processes.
But design is only the the first step of the value chain. Once the garment is designed, it is time to shoot it so the sales team can sell faster to wholesalers or directly to customers (through your website or marketplaces). To do so, AI can help transform photo shoots from a logistical hassle into a smooth, cost-efficient process.
II/ AI for photoshoots: Virtual try On and AI-generated model
Virtual Try-On uses AI to dress models in garments digitally. It creates on-model photos from product images without the need for a physical photo shoot. This simplifies and reduces the cost of fashion imagery, revolutionizing how we approach fashion photography.
1) AI Generated Models for Virtual Try On
Some brands are integrating virtual try‑on directly into their product detail pages, not for customer personalization but to generate the product imagery itself. Instead of organizing traditional photoshoots, teams can now manage the entire process internally: selecting the model, defining the styling, choosing the set design, and producing consistent on‑model images at scale. What begins as a change in photography workflow quickly becomes a transformation of the broader marketing production process.
An example of a major brand that has taken the leap is Mango. According to Arcadian, the company has begun replacing conventional product photos with AI‑generated visuals across its PDPs. These images maintain a premium, editorial look while offering full control over poses, lighting, and styling. The result is a faster, more flexible production pipeline and a highly uniform visual identity across collections. This approach signals a new era for e‑commerce, where AI‑generated try‑on imagery becomes a core component of product presentation rather than an optional enhancement.
2) Virtual Try-On Based on Existing Models
A second form of AI-powered imagery is emerging alongside fully digital visuals: virtual try-on based on existing models. Rather than generating an avatar from scratch, this approach creates what the industry calls a "digital clone": a faithful digital replica built from scans or photographs of a real model, capable of being restyled and redeployed across any collection without the model ever setting foot on set.
H&M was one of the first major brands to adopt this technique at scale. The Swedish retailer partnered with a leading tech firm to develop a roster of digital twins of real models, generating an endless stream of on-model e-commerce imagery — without a single traditional photoshoot.
II/ AI in Marketing Campaigns
The creation of fashion marketing campaigns, once a lengthy and resource-intensive process, is being completely transformed by a new generation of sophisticated AI platforms.
1) Enterprise-Grade Scaling with Adobe Firefly
The adoption of generative AI at the enterprise level is accelerating, with major corporations integrating tools like Adobe Firefly to fundamentally rethink their content production pipelines. The Estée Lauder Companies (ELC), whose portfolio spans nearly 25 brands including Clinique, M•A•C Cosmetics and La Mer, partnered with Adobe to adopt Firefly Services across its operations in roughly 150 countries. The scale of the challenge is telling: campaigns across digital channels generate hundreds of thousands of assets each year, leaving creative teams spending more time on repetitive resizing tasks than on actual creative work. By integrating Generative Expand directly into existing workflows, ELC can now intelligently resize and optimize images across formats, freeing designers to focus on high-impact storytelling. A clear signal that AI is becoming core infrastructure, not just a creative add-on, for global content operations.

Adobe Firefly
2) Virtual Try On for a strong Marketing Impact
Beyond image generation, social media platforms are also reinventing brand engagement through AI. Snapchat has introduced Sponsored AI Lenses, a new advertising format powered by its proprietary generative AI technology.
For the luxury sector, this technology opens particularly compelling possibilities. Gucci became one of the first luxury houses to embrace this format, launching the "Famiglia" Sponsored AI Lens in collaboration with Snapchat — presented as the very first AI lens of its kind developed for the luxury industry. The experience, accessible from Gucci's official Snapchat profile and available across selected markets including France, the UK, the UAE, and Saudi Arabia, invites users to take a selfie and merge it with one of the brand's iconic Famiglia silhouettes — Incazzata, Il Figo, Principino, and others. Rather than simply admiring a campaign, users are invited to become part of it — a fundamental shift in how luxury communicates with its audience. As Geoffrey Perez, Global Head of Luxury at Snap Inc., noted, generative AI opens a new field of expression for luxury houses, moving from passive admiration to active participation in brand storytelling.

©Snap Inc.
III/ AI in Sales & Customer Experience
In 2025, artificial intelligence has moved from a back-end operational tool to a front-line, customer-facing force. The most significant advancements are happening at the point of sale and service, with a new generation of AI-powered assistants and platform integrations.
1) The Rise of Conversational Commerce
The era of the AI Shopping Assistant has arrived, with the market projected to grow from $4.3 billion in 2024 to nearly $42 billion by 2034. These intelligent digital agents are moving beyond simple chatbots to become sophisticated personal stylists.
In a major development in September 2025, Ralph Lauren launched "Ask Ralph" a conversational AI shopping experience powered by Microsoft Azure OpenAI. The platform understands open-ended, natural language prompts from customers and provides tailored styling inspiration from available inventory. Similarly, Daydream, an AI-powered fashion chatbot from e-commerce veteran Julie Bornstein, launched in June 2025 after a $50 million seed round, allowing users to find clothing by typing queries like "I want a dress for a wedding in Paris" or by uploading images for visual search.
The adoption rate is significant: in 2025, 48% of Millennials reported using AI shopping assistants or ChatGPT to facilitate their online purchases, and these assistants achieve 3 times higher engagement than human creators.

Ask Ralph Lauren App | source: Ralph Lauren Corporation
2) AI Integration in Core E-commerce Platforms
AI is no longer an add-on; it is being woven directly into the fabric of the major platforms that power e-commerce. Shopify has introduced numerous AI-powered features for fashion brands in 2025. These include AI-driven personalization that adjusts a store's content based on a user's location and past interactions, as well as powerful product recommendation tools.
Salesforce has also made significant AI innovations, launching its Einstein 1 Platform to connect retail data seamlessly with large language models. Key tools include the Einstein Copilot for Shoppers, which provides personalized shopping assistance, and Agentforce, an autonomous AI suite that improves efficiency in customer service, sales, and marketing.
3) Customer Service, Reimagined on WhatsApp
Fashion brands are increasingly turning to WhatsApp as the new front door for customer service. Takko Fashion, a German value retailer with nearly 2,000 stores across 17 countries and revenues exceeding €1 billion, leads this shift.
Partnering with charles, Takko deployed WhatsApp as a direct channel with automated, personalized message flows, audience segmentation, and an in-store barcode voucher system letting customers redeem discounts straight from their phone.
The results are striking: 88% message open rates, 17% click-through rates, and subscriber growth of 2,000+ per month, with an 82% uplift in in-store revenue during active campaigns and a 36.8x ROAS.
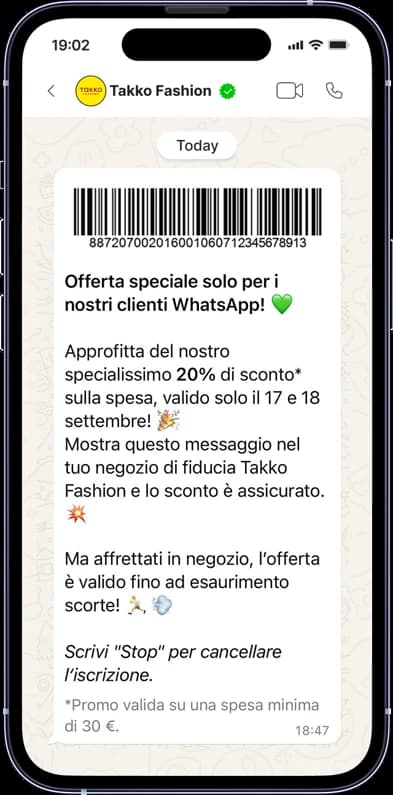
Takko Fashion Campaign
4) Personalized product recommendations
Generative AI also excels in personalized product recommendations. Consider a customer browsing your online store. With AI-driven recommendations, they see products that match their preferences, increasing the likelihood of a purchase.
Recommendation engines are algorithms designed to predict and suggest items that a user may be interested in based on their past interactions, preferences, and behavior. For example, retail giants like Amazon use NLPs to understand customer preferences and tailor recommendations accordingly.
Personalized recommendations enhance the shopping experience, driving higher conversion rates. Indeed, McKinsey noted that 35% of what shoppers buy on Amazon comes from product recommendations
5) Virtual Try-On to improve Customer Experience
Zara's new tool perfectly illustrates the integration of AI into the customer experience. As reported in Woman & Home, the feature lets visitors create a full‑body avatar from just two photos and then visualize outfits directly on their digital self. The journalist, initially skeptical, describes being impressed by the realism of the fit, the natural proportions, and the ability to rotate the avatar for a 360° view. The tool removes much of the guesswork from online shopping, making the experience more playful, more personal, and far more confidence‑boosting.

But brand-specific tools may already be facing a stronger competitor: Google. Doppl, an experimental virtual try-on app from Google Labs, lets users upload a photo of themselves and try on outfits from a range of sources. The app is set to close on April 30, 2026: not because it failed, but because the technology is being folded into Google's existing products. Virtual try-on will then be accessible on product listings and apparel image search results across Google.
For fashion brands, the signal is clear: virtual try-on is becoming search infrastructure, rather than a competitive advantage any single brand can own.
IV/ AI in Operations & Supply Chain
While customer-facing AI applications often capture the headlines, an equally profound transformation is happening in the operational back-end of the fashion industry. In 2026, AI is being integrated into the core systems that manage everything from product data to supply chain logistics, driving unprecedented efficiency, intelligence, and sustainability.
1) The Intelligent Asset: AI-Powered PIM & DAM
The management of product information and digital assets is undergoing a revolutionary AI-powered upgrade.
Product Information Management (PIM) systems now use AI to automate highly manual tasks. Advanced solutions like PIMinto's AI assistant can automatically write compelling product descriptions from technical specifications, enrich existing data, and even translate content into multiple languages. This increases the accuracy of product data while freeing human teams to focus on more strategic initiatives.
Digital Asset Management (DAM) systems now feature sophisticated, fashion-specific AI. Platforms like Pics.io use AI to automatically generate relevant fashion tags for images, covering details like colors, styles, and patterns. These systems also offer AI-powered visual search, allowing teams to find assets based on descriptive queries without relying on manual tags.

Basecamp | Pics.io | PIMinto logos
2) AI in Inventory Forecasting
AI is providing a powerful solution to one of fashion’s most persistent challenges: unpredictable demand, which can lead to costly overstock and waste. New platforms are transforming inventory management from a reactive process into a predictive science by analyzing vast datasets, including historical sales and real-time market trends.
Companies like Autone are at the forefront of this shift, offering AI-powered tools that help brands optimize their stock levels to maximize profitability. Similarly, platforms such as Metreecs provide real-time analytics that can automate key decisions like stock replenishment. The integration of this technology enables a more efficient and profitable supply chain, with the potential to reduce forecast errors and costly overstock.
3) Automated Product Page Descriptions
Platforms like Velou specialize in this for e-commerce, using AI to analyze product attributes and generate high-quality copy that can reduce the time-to-market for new products by up to 80%. Competitors like Jasper, a versatile AI writing assistants, offer specific templates for fashion product descriptions. By automating this crucial step, these tools free up marketing teams to focus on broader strategic initiatives.
4) Optimize your supply chain through inventory management and trends predictions.
In 2026, fashion brands face rising tariffs, volatile demand, and tighter margins. The State of Fashion 2026 highlights that operational efficiency has become a top priority, and AI is now central to building more resilient supply chains.
AI‑driven forecasting helps brands anticipate demand shifts, adjust production earlier, and avoid costly overstock or stockouts. As global sourcing networks are being reshaped, companies that integrate AI into planning can rebalance suppliers, shorten lead times, and react faster to market changes.
In fact, AI is already helping manage inventory levels, reducing overstock and stockouts. The French Startup Ako utilizes advanced AI technology to revolutionize supply chain management in the fashion industry. It enhances operational efficiency by forecasting demand, optimizing inventory, and streamlining supply planning with real-time insights.
5) AI Photoshoots to optimize the shooting process
Beyond cost and speed, brands can now optimize their entire photo production chain through AI-generated photoshoots. This technology offers a powerful solution to casting challenges that have long constrained creative teams: whether sourcing hard-to-find demographics such as children, where strict labor regulations apply, or building a truly diverse roster of plus-size models on demand.
Specialized platforms like Veeton are engineered to solve this exact problem, enabling brands to generate a diverse range of on-demand, photorealistic models that align with any specific creative or demographic need. This approach gives brands a powerful tool for creating consistent, high-impact content while maintaining full creative and legal control.
If you found this article insightful, you're likely curious about the technologies that are actively redefining the fashion industry. As we've seen, AI has moved beyond experimentation to become a concrete and accessible lever for performance.
Ready to move from theory to practice? Discover how Veeton’s technology puts these innovations directly into your hands. Sign up and start transforming your visual production today.